| Page Loading and Pooling | ||
|---|---|---|
 | Chapter 4. Tapestry Pages |  |
| Page Loading and Pooling | ||
|---|---|---|
| | Chapter 4. Tapestry Pages | |
The process of loading a page (instantiating the page and its components) can be somewhat expensive. It involves reading the page's specification as well as the specification of all embedded components within the page. It also involves locating, reading and parsing the HTML templates of all components. Component bindings must be created and assigned.
All of this takes time ... not much time on an unloaded server but potentially longer than is acceptable on a busy site.
It would certainly be wasteful to create these pages just to discard them at the end of the request cycle.
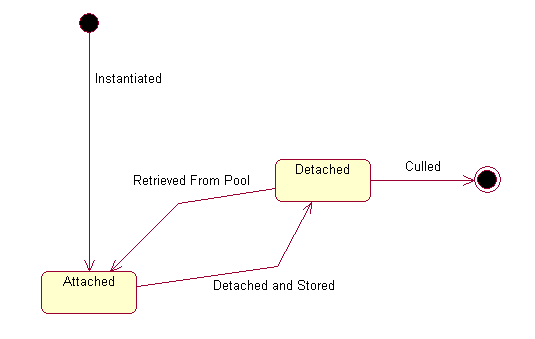
Instead, pages are used during a request cycle, and then stored in a pool for later re-use. In practice, this means that a relatively small number of page objects can be shared, even when there are a large number of clients (a single pool is shared by all clients). The maximum number of instances of any one page is determined by the maximum number of clients that simultaneously process a request that involves that page.
As the page is retrieved from the pool, all of its persistent page properties are set. Thus the page is equivalent to the page last used by the application, even if it is not the same instance. This includes any state (that is, the settings of any instance variables) that are particular to the client.
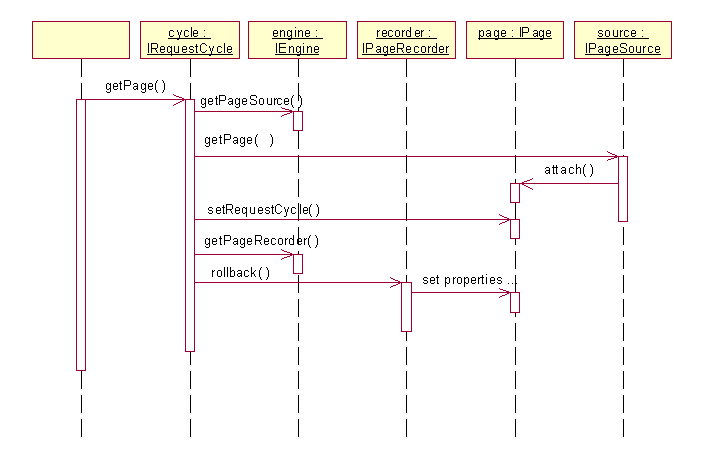
This process is managed by the IRequestCycle. When asked for a page, it checks whether the page has
been accessed yet for this request. If not, the page must be obtained from the page loader and properly
attached and configured.
The page loader maintains a pool of pages, or can construct a new page instance as needed. The
IPageRecorder for the page tracks the persistant page properties and can reset the properties
of the page instance to values appropriate to the current session.
A page is taken out of the pool only long enough to process a request for a client that involves it. A page is involved in a request if it contains the component identified in the service URL, or if application code involves the page explicitly (for instance, uses the page to render the HTML response). In either case, as soon as the response HTML stream is sent back to the client, any pages used during the request cycle are released back to the pool.
This means that pages are out of the pool only for short periods of time. The duration of any single request should be very short, a matter of a second or two. If, during that window, a second request arrives (from a different client) that involves the same page, a new instance will be created. Unless and until that happens, a single instance will be used and re-used by all clients, regardless of the number of clients.
Pages stay in the pool until culled, at which point the garbage collector will release the memory used by the page (and all the components embedded in it). The default behavior is to cull unused pages after approximately ten minutes.
| |  | |
| Stale Links and the Browser Back Button |  | Page Localization |