-
How do I integrate a Tapestry application with J2EE declarative security/JAAS?
-
In Tapestry 3.0, this could be a problem, because of the way Tapestry generated
URLs. Tapestry 4.0 adds native support for
friendly URLs
which allow you to modularize your application across multiple folders in a more
traditional manner.
-
What is the
Script
component? Why is it needed and how does it work?
-
One of the challenges in building a component framework for the web is
addressing client-side scripting. In the Tapestry world, a component may be used
multiple times within a single page, or even rendered multiple times within a
loop. This creates issues when that component is expected to have client-side
behavior because the same component will render out as many HTML elements with
different names, and naming conflicts could break the behavior on the client
side.
The challenge is to adapt the JavaScript to the particular names related to a
specific component. This requires a special templating language just for
generating JavaScript.
IMO, this script templating framework is an effective means to bundle scripts in
components. It provides scripts with the advantages of components. It can now be
reused like a component and not have to worry about renaming field names or the
wiring between the fields and the scripts. You just declare the component and
you are good to go. It certainly is another layer of abstraction that one will
have to learn but once you have learned it, it is very powerful. And honestly
there is not much to it.
The script framework is mandated by the fact that form element/field names are
automatically generated by the framework. And so you write your script in XML
and use variables for these names and let the framework provide the correct
names during runtime. Going further, you may also ask the framework to provide
other objects that would help in creating your script. For example...
<![CDATA[
<input-symbol key="select"
class="org.apache.tapestry.form.PropertySelection"
required="yes"/>
]]>
This defines an input variable "select" of type
"org.apache.tapestry.form.PropertySelection". All such variables/symbols passed
in to the script is stored in a symbol map. And now you can use the form select
list name by using an ant style syntax like ${select.name}. The expression
within "${}" is an OGNL expression and is evaluated with respect to the symbol
map. You may also define your own symbols/variables using let... like...
<let key="formObj">
document.${select.form.name}
</let>
<let key="selectObj">
${formObj}.${select.name}
</let>
These variables/symbols are stored in the symbol map also. So now if you want to
set the value of the form select list all you do is say
${formObj}.${selectObj}.value = 'whatever'; this would be equivalent to
document.myForm.mySelect.value = 'whatever';
where
myForm
is the form name and mySelect is the select list name.
input-symbols are like method parameters and
lets are like
instance variables. Typically you would pass values to the
input-symbols via the Script component like...
<component id="myScript" type="Script">
<binding name="script" value="ScriptSpecificationName.script"></binding>
<binding name="select" value="components.somePropertySelection"></binding>
</component>
The actual scripts are defined in one of the two sections of the script
specification, body... or initialization..., depending on when
you want the script to execute. If you want the script to execute on load of the
page, then you define it in the initialization..., if you want it to
execute on any other event, define it in the body... section of the
specification. For example...
<body>
function onChangeList(listObj)
{
alert(listObj.value);
}
</body>
<initialization>
${selectObj}.onchange = function(e)
{
onChangeList(${selectObj});
}
</initialization>
The JavaScript generated inside the body element (of the script
template) is ultimately rendered into a single JavaScript block located just
inside the HTML body tag. The intialization content is placed in
a second JavaScript block, just before the HTML /body tag.
One more thing to remember, scripts being components, and components by nature
being independent of its environment, will render the script in the page once
for every ocurrance of the component. If you want the body of the script to be
rendered only once no matter how many times the component is used, just wrap the
body in a unique tag like...
<body>
<unique>
function onChangeList(listObj)
{
alert(listObj.value);
}
</unique>
</body>
That's all there is to it!
-
cycle.activate() does not seem to alter the URL. Is there any alternative that will
alter the URL to point to the correct page?
-
You would need to throw a RedirectException with the new URL; this sends an HTTP
redirect to the client.
- How do I do page navigation like Struts?
-
Usage page meta-data:
Page1.page
<page-specification>
...
<meta key="success" value="Home"></meta>
<meta key="error" value="Error"></meta>
</page-specification>
Page2.page
<page-specification>
...
<meta key="success" value="ClientInfo"></meta>
<meta key="error" value="SecurityCheck"></meta>
</page-specification>
public void submitListener(IRequestCycle cycle)
{
String key = ifSuccess() ? "success" : "error";
String pageName = getSpecification().getProperty(key);
cycle.activate(pageName);
}
-- Tip from Harish
- How do I make a link popup a new window?
-
Use the contrib:PopupLink component.
- How do I stream a file to the user from Tapestry?
-
Make a method like the following a a listener, such as from a DirectLink or
whatever.
(The Document is just a class that holds the file information you want to send
to the user.)
public void downloadAction(IRequestCycle cycle)
{
try
{
HttpServletResponse response =
cycle.getRequestContext().getResponse();
byte[] data = new byte[1024];
FileInputStream in = document.getFileInputstream();
response.setHeader("Content-disposition",
"inline; filename=" +
document.getFileName());
response.setContentType(document.getMimeType());
response.setContentLength(new Long(document.getSize()).intValue());
ServletOutputStream out = response.getOutputStream();
int bytesRead = 0;
while ((bytesRead = in.read(data)) -1)
{
out.write(data, 0 , bytesRead);
}
in.close();
response.flushBuffer();
}
catch (IOException e)
{
e.printStackTrace();
}
}
This is not sanctioned by Howard. The correct approach is to define a new engine
service for accessing the content, and build a URL to that content, possibly
sending a redirect to the client to load that content. This approach has not be
verified to work in Tapestry 4.0.
-
I need to calculate a URL to jump to a particular page. How do I do this?
-
The best bet is to use the external service. This lets you directly invoke a
page and pass objects as parameters. The page you want to jump to will need to
implement IExternalPage. To calculate the URL you have to use something like
this:
// Add <inject property="externalService" object="engine-service:external"></inject> to specification
// or use @InjectObject("engine-service:external")
public abstract IEngineService getExternalService();
public String getURL(IRequestCycle cycle, String pageName, Object[] parameters)
{
IEngineService service = getExternalService();
ExternalServiceParameter parameter = new ExternalServiceParameter(pageName, parameters);
ILink link = service.getLink(cycle, parameter);
return link.getURL();
}
Different engine services take different types of objects as that final
parameter.
-
I have a form with a submit button. On the form and the submit button are two
separate listeners. Which is invoked first?
-
The listener for the Submit (or ImageSubmit, or LinkSubmit) component will
always trigger first; the Form's listener always triggers last.
The timing on the Submit listener can be confusing. In Tapestry 3.0, the Submit
listener would be invoked in the middle of the form's "rewind"; and in some
cases, properties (set by components "further down" the form) would not have
been set yet.
In Tapestry 4.0, the execution of the listener method is deferred until just
before the form's listener by default. This can be turned off using the Submit's
defer parameter.
-
I'd like to be able attach my own client-side javascript handling on the form
submit. What's the best way to do this?
-
You can add event handler during component rendering:
protected void renderComponent(IMarkupWriter writer, IRequestCycle cycle){
...
yourFormComponent.addEventHandler(FormEventType.SUBMIT, "javaScriptValidatingFunctionName");
...
}
org.apache.tapestry.contrib.palette.Palette
can be used for detailed example.
Warning:
This is about to change significantly for Tapestry 4.0, with the bulk of the
client-side event handling moving to the client side.
- What's the lifecycle of a form submit?
-
Events will trigger in the following order:
- initialize()
- pageBeginRender() ("rewind")
- rewind of the form / setting of properties
- Deferred listeners (for Submit components)
- Form's listener
- pageEndRender() ("rewind")
- pageBeginRender() (normal)
- pageEndRender() (normal)
The form "rewind" cycle is nothing more than a render cycle where the output is
buffered and scrapped rather than written to the servlet output stream. The
second pageBeginRender() is triggered during the actual page rendering. You can
use requestCycle.isRewinding() to distinguish between these two render cycles.
- Can I use the same component multiple times in one template?
-
No - but you can copy the definition of a component pretty easily.
<component id="valueInsert" type="Insert">
<binding name="value" value="getValueAt( rowIndex, columnIndex )"></binding>
</component>
<component id="valueInsert1" copy-of="valueInsert"></component>
<component id="valueInsert2" copy-of="valueInsert"></component>
<component id="valueInsert3" copy-of="valueInsert"></component>
<component id="valueInsert4" copy-of="valueInsert"></component>
-
I have to restart my application to pick up changes to specifications and templates,
how can I avoid this?
-
Start your servlet container with the JVM system parameter
org.apache.tapestry.disable-caching
set to true, i.e.,
-Dorg.apache.tapestry.disable-caching=true
.
Tapestry will discard cached specifications and templates after each request.
You application will run a bit slower, but changes to templates and
specifications will show up immediately. This also tests that you are persisting
server-side state correctly.
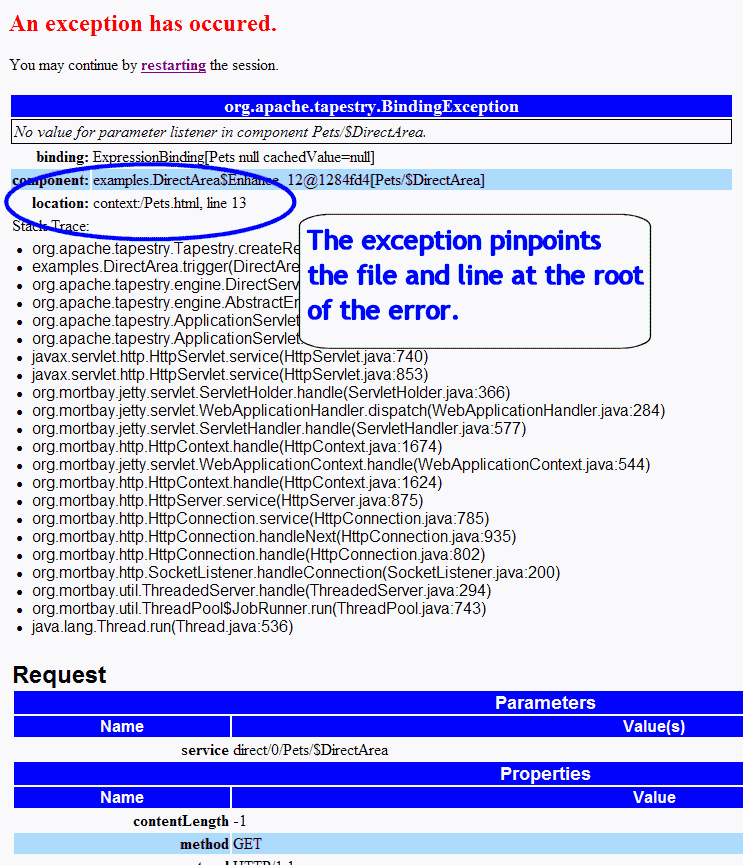
- What is "line precise error reporting"?
-
Tapestry applications are built from templates and specifications. It's natural
that when these templates and specifications are read, any syntax errors are
reported, and the precise file and location is identified.
Tapestry goes far beyond that! It always relates runtime objects back to the
corresponding files so that even runtime errors report the file and location.
For example; say you bind a parameter of a component that expects a non-null
value, but the value ends up being null anyway, due to a bug in your code or
your specification. Tapestry can't tell, until runtime, that you made a mistake
... but when it does, part of the exception report will be the line in the
template or specification where you bound the component parameter. Zap! You are
sent right to the offending file to fix the problem.
Other frameworks may report syntax errors when they parse their specifications,
but after that, you are own your own: if you are lucky, you'll get a stack
trace. Good luck finding your error in that! Tapestry gives you a wealth of
information when unexpected exceptions occur, usually more than enough to
pinpoint the problem
without
having to restart the application inside a debugger.